Hi,大家好,我是半亩花海。本实验本项目基于 VGG16-UNet 架构,利用 Labelme 标注数据和迁移学习,构建高效准确的猫狗图像分割模型。通过编码器-解码器结构(特征提取-上采样)提升分割精度,适应不同场景,推动图像分割技术发展。(想要改写成论文的可以加上摘要和绪论[主要介绍项目的研究背景和意义等])
目录
一、数据预处理
1.1 猫狗数据集的图像特征
1.2 图像数据标注
1.3 JSON 转换成 PNG
1.4 生成 JPG 图片和 mask 标签的名称文本
1.5 数据文件夹结构
1.6 划分数据集
1.7 读取部分图片查看像素值
1.8 图片标签处理
二、分割网络模型
2.1 编码器——VGG16 预训练模型
2.2 解码器——UNet 网络
2.3 VGG16-UNet 模型架构
三、环境配置与性能衡量
3.1 环境配置
3.2 损失函数
3.3 评价指标
四、模型训练与预测
4.1 模型训练
4.1.1 模型训练过程
4.1.2 猫狗图像分割训练结果
4.2 模型预测
4.2.1 待预测猫狗图像的模型分割过程
4.2.2 预测结果可视化
五、总结与展望
5.1 总结
5.2 展望
参考文献
一、数据预处理
数据预处理是整个深度学习流程中至关重要的一环,通过对原始数据进行整理和转换,能够为模型训练提供高质量、格式统一的数据。
1.1 猫狗数据集的图像特征
掌握猫狗的图像特征是优选针对性图像处理方法、精准识别与评价猫狗的前提。待数据标注的猫狗图像,通常表现的特征包括以下 5 点:
- 颜色特征:猫和狗的毛发颜色各异,从白色到黑色、从单色到多色,这些颜色特征在图像处理中是重要的标注依据。
- 形状特征:猫的身体通常较为柔软,有流线型的身体和圆形的头部特征,而狗的形状则更多样化,有些品种有较长的身体和四肢,头部形状也各异。
- 纹理特征:不同品种的猫狗毛发纹理差异明显,有的毛发较为顺滑,有的则卷曲或粗糙,纹理特征有助于分辨不同种类的猫狗。
- 姿态特征:猫狗在不同状态下的姿态差异显著,猫的动作通常较为灵活优雅,而狗则有多种活动姿态,从奔跑到坐卧不一。
- 面部特征:面部特征是识别猫狗的关键,猫有大而圆的眼睛,狗的面部特征则因品种不同差异较大,包括耳朵的形状、鼻子的大小等。

图 1-1 猫狗原数据集
由上述原因以及图1-1可知,猫狗的图像处理需要精确提取上述特征,以确保在后续的识别与分类中能够取得更高的准确性和鲁棒性。因此,本文设计了 VGG16-UNet 语义分割模型提取猫狗图像轮廓。
1.2 图像数据标注
使用 Labelme 标注工具,采用点标记法(Create Polygon)对 500 个猫狗待分割图像进行轮廓标注,类别为“cat”和“dog”,数据集标注过程如图 1-2 所示。
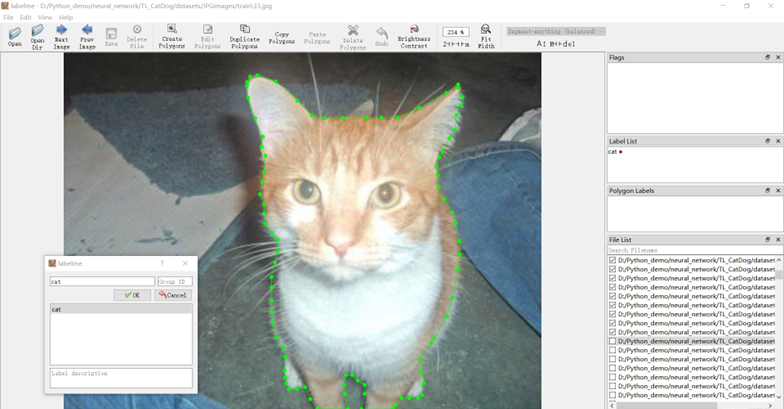
图 1-2 数据集标注过程
标注完成后会在同一指定目录下(./datasets/Annotation/)生成 JSON 文件,文件内容主要包括version(labelme版本)、label(标签类别)、points(各个点坐标)、imagePath(图像路径)、imageHeight(图像高度)、imageWidth(图像宽度)。
1.3 JSON 转换成 PNG
在语义分割任务中,通常使用 JSON 格式存储标注信息,而模型训练需要以图像格式(如 PNG)提供标注数据。因此,需要将 JSON 转换为 PNG 格式。
- 读取 JSON 文件:首先读取包含标注信息的 JSON 文件。
- 解析标注数据:解析 JSON 文件,提取标注信息,包括类别和像素位置。
- 生成 PNG 文件:根据解析的标注信息生成对应的 PNG 文件。每个类别用唯一的颜色值表示,生成的 PNG 文件用于后续模型训练中的标签。

图 1-3 JSON 转换成 PNG
1.4 生成 JPG 图片和 mask 标签的名称文本
为了方便管理和加载数据,我们将所有图像文件(JPG)和对应的 mask 标签文件(PNG)的文件名记录在一个文本文件中。
- 读取文件名:遍历存放图像和标签的文件夹,获取所有文件的名称。
- 匹配文件名:确保每个图像文件都有对应的标签文件。
- 保存文件名:将图像文件名和标签文件名按行写入一个文本文件,每行记录一对图像和标签文件名,用分号分隔。
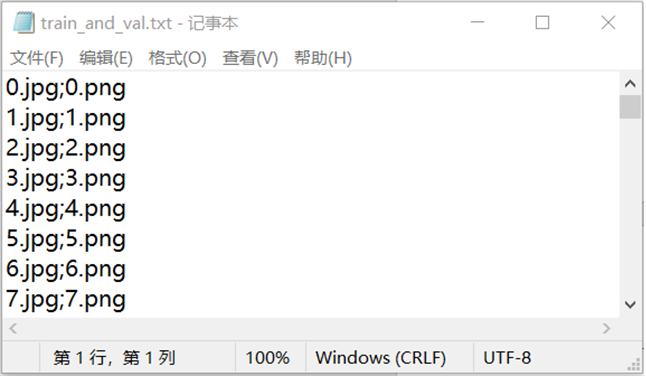
图 2-4 生成 JPG 图片和 mask 标签的名称文本
1.5 数据文件夹结构
构建迁移学习数据集,TL_CatDog 文件夹的结构及相应的解释如下:
TL_CatDog/
├── datasets/
│ ├── Annotations/
│ ├── JPEGImages/
│ ├── test/
│ └── train
│ ├── Segmentation/
│ ├──train_and_val.txt/
│ ├── SegmentationClass
├── ckpt_UNet/
│ ├──ep_{}-loss_{}-val_loss_{}.h5
├── CatDog_VGG16-UNet.ipynb
注:
ckpt_UNet 是训练权重
Annotations 是标注后的 JSON 文件
JPEGImages 是猫狗原图
train_and_val.txt 是数据集名称和 png 图像名称
SegmentationClass 是语义分割的 mask 标签的 png 图像
1.6 划分数据集
数据集的划分对模型的训练和评估至关重要。我们将数据集按照 90% 训练集和 10% 验证集的比例进行划分。具体方法是:
- 读取数据列表:读取记录所有图像和标签文件名的文本文件。
- 打乱数据顺序:为了确保数据分布的随机性,先对数据列表进行随机打乱。
- 按比例划分:按 90% 为训练集、10% 为验证集进行数据集划分。
- 保存划分结果:将划分结果保存到相应的文本文件中,供后续使用。
# 加载数据集并预处理
with open("./datasets/Segmentation/train_and_val.txt", "r") as f: # 打开训练和验证数据文件
lines = f.readlines() # 读取所有行
# 打乱数据
np.random.seed(10101) # 设置随机种子
np.random.shuffle(lines) # 打乱数据集
np.random.seed(None) # 重置随机种子
num_val = int(len(lines) * 0.1) # 10% 用于验证
num_train = len(lines) - num_val # 90% 用于训练
1.7 读取部分图片查看像素值
在语义分割任务中,标签图像的像素值表示不同的类别。检查标签图像的像素值有助于确认数据的正确性和类别分布。
- 读取图像:使用图像处理库读取标签图像。
- 获取像素值:提取图像的所有像素值,并去重。
- 打印像素值:打印每个唯一的像素值,以检查标签图像的类别信息。
# 读取部分图片查看像素值
def values(image_path):
image = Image.open(image_path) # 打开图像
pixels = list(image.getdata()) # 获取像素值
unique_pixels = set(pixels) # 去重像素值
# 打印每个唯一像素的RGB值
for pixel_value in unique_pixels:
print(f"去重后像素值: {pixel_value}")
# 指定要检查的图像路径
image_path = "./datasets/SegmentationClass/467.png"
values(image_path) # 查看图像的唯一像素值
通过查看 SegmentationClass 文件夹里的第 467 张图片的像素值,结果如下。
表 2-1 像素值查看结果
| 去重后像素值 | 含义 |
| 0 | Background(黑色) |
| 1 | cat(红色) |
| 2 | dog(绿色) |
1.8 图片标签处理
为了将标签图像转换为模型可用的格式并批量处理数据,需对标签进预处理。
- 数据生成器:定义一个生成器函数,按批次读取图像和标签数据。
- 图像和标签预处理:调整大小、归一化、灰度转换、one-hot 编码。
- 生成批次数据:将预处理后的图像和标签打包成批次,并生成给模型训练。
# 图片标签处理
def generate_arrays_from_file(lines, batch_size):
n = len(lines) # 获取数据行数
i = 0 # 初始化索引
while 1: # 无限循环,生成数据
X_train = [] # 初始化训练输入数据列表
Y_train = [] # 初始化训练标签数据列表
for _ in range(batch_size): # 每批次处理的图像数
if i == 0:
np.random.shuffle(lines) # 随机打乱数据
# 读取输入图片并进行预处理
name = lines[i].split(';')[0] # 获取图像文件名
img = Image.open("./datasets/JPEGImage/train/" + name) # 打开图像文件
img = img.resize((WIDTH, HEIGHT), Image.BICUBIC) # 调整图像大小
img = np.array(img) / 255 # 归一化处理
X_train.append(img) # 添加到训练数据列表
# 读取标签图片并进行预处理
name = lines[i].split(';')[1].split()[0] # 获取标签文件名
label = Image.open("./datasets/SegmentationClass/" + name) # 打开标签文件
label = label.resize((int(WIDTH / 2), int(HEIGHT / 2)), Image.NEAREST) # 调整标签大小
if len(np.shape(label)) == 3: # 如果标签是彩色的
label = np.array(label)[:, :, 0] # 转换为灰度图
label = np.reshape(np.array(label), [-1]) # 将标签展开为一维
one_hot_label = np.eye(NCLASSES)[np.array(label, np.int32)] # 转换为one-hot编码
Y_train.append(one_hot_label) # 添加到标签数据列表
i = (i + 1) % n # 更新索引,循环到开头
yield np.array(X_train), np.array(Y_train) # 生成一个批次的数据和标签
二、分割网络模型
语义分割中编码器-解码器结构是研究语义分割方面普遍使用的一种结构,由编码器、过渡层和解码器共同组成。其主要思想是将输入的图像分别经过编码器和解码器两个部分,最终得到像素级别的语义分割结果。
- (1)编码器负责通过下采样降低图像维度;
- (2)过渡存在于编码器和解码器之间,提取并传递高维征信息;
- (3)解码器负责通过上采样将特征图还原原始维度。
2.1 编码器——VGG16 预训练模型
VGG16 预训练模型是一种卷积神经网络,通过在 ImageNet 等大规模数据集上的预训练,学习到丰富的特征表示,广泛应用于图像分类、目标检测和图像分割等任务[1]。VGG16 包含 16 个可训练层(13 个卷积层和 3 个全连接层),作为编码器,它通过其卷积层提取图像中的高层次语义信息,并通过池化层进行降维处理,从而有效保留关键特征。这些特征图包含了输入图像的高层次语义信息,可以有效地提取图像中的物体和背景等信息,从而加速模型收敛并提高性能。
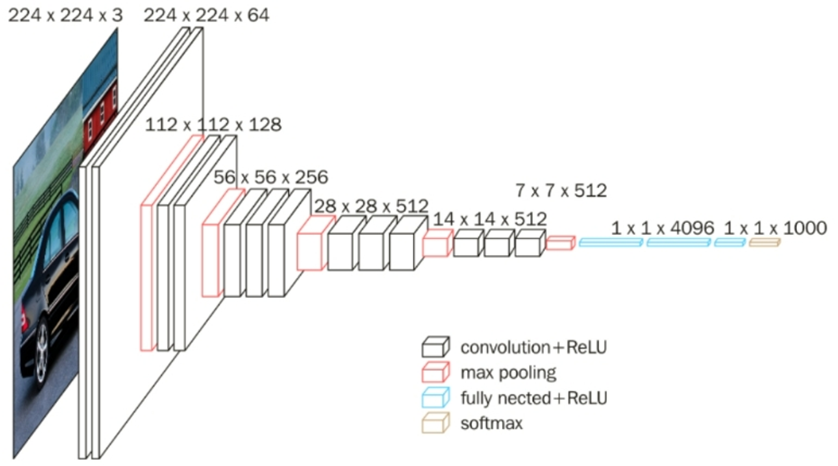
图 2-1 VGG16 模型结构图
这里只采用 VGG16 的前 4 次特征提取能力作为编码器,将 VGG16 权重加载加入编码器部分,使其可以利用已经训练好的权重进行特征提取,帮助节省训练时间,提取效果更好。
2.2 解码器——UNet 网络
UNet 网络是一种常用于图像分割的深度学习模型,其解码器部分将编码器提取的特征图进行上采样和重建,逐步恢复图像的空间分辨率,最终得到像素级别的语义分割结果[2]。
在本文中 UNet 作为解码器,主要由 3 个上采样层构成,每个采样层将输入沿着横向和纵向分别放大两倍,即每个像素变为一个 2×2 的方块,此时,特征图的高度和宽度被放大两倍。在每个上采样步骤中,将高分辨率的特征图与编码器对应层的特征图通过跳跃连接的方式进行拼接融合,充分利用上下文信息,以便保留更多的细节信息。重复进行上采样、填充、卷积和批归一化操作后,通过 3×3 卷积核生成输出层和零填充,实现 3 个表型类别的输出。
通过这种方式,UNet 不仅能恢复图像尺寸,还能提高分割精度。为了更容易计算训练过程中的损失值,解码器在上采样过程中生成与标签类似的输出。UNet 网络广泛应用于医学影像分割、遥感图像处理等领域,因其高效的特征融合和精确的分割能力而备受青睐。

图 2-2 UNet 模型结构图
其中,本实验中使用到的 UpSampling2D 为上采样操作,BatchNormalization 为批归一化操作。ZeroPadding2D 操作的目的是在图像边界进行零填充,为了在后续的卷积操作中避免尺寸缩小。
2.3 VGG16-UNet 模型架构
将编码器与解码器通过过渡连接在一起,编码器通过多个卷积层和池化层逐渐减小特征图的空间分辨率,同时提取抽象的语义特征[3]。解码器通常包括上采样层等,通过逐步上采样将特征图的分辨率增加,同时进行一些操作以恢复细节和位置信息。最终的输出是一个与输入图像具有相同尺寸的分割图[4]。
本模型 VGG16-UNet 结合了 VGG16 编码器和 UNet 解码器,由编码器提取特征,再通过解码器进行上采样,最终输出分割结果。VGG16-UNet 模型的大致结构如图 2-3 所示。
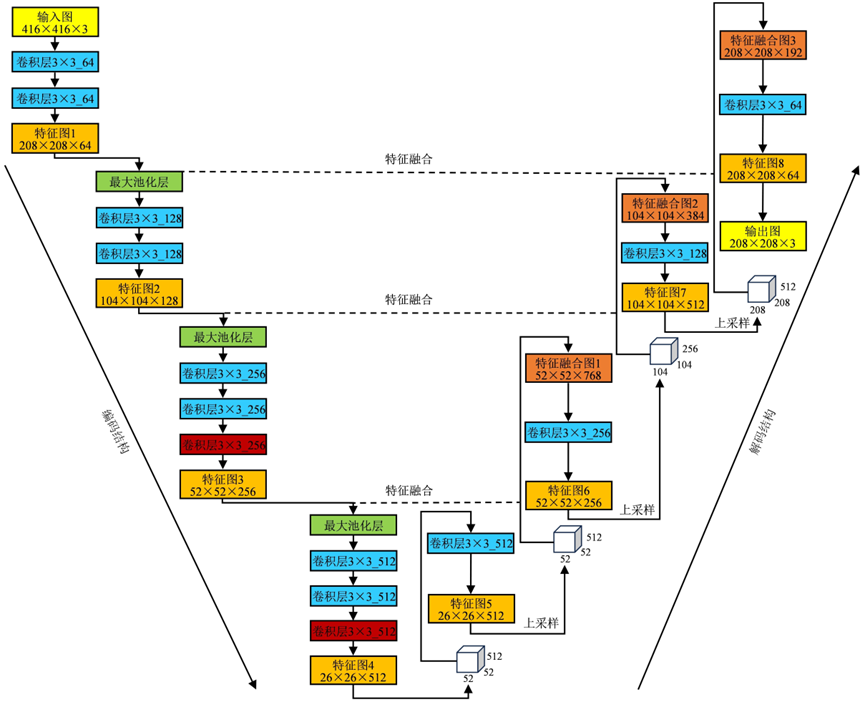
图 2-3 VGG16-UNet 模型结构
本文的 VGG-UNet 网络中,卷积操作用于特征提取, 绝大部分使用的卷积核(kernel)大小为 3×3,步长(striding)为 1,各边缘使用零填充(padding),这样保证了卷积前后的长宽不变;最大池化操作使用 2 倍下采样,用于降低维度和减少噪声。反卷积操作采用 2 倍上采样,用于维度的恢复。跳跃连接则主要用于底层的空间位置信息与深层特征的语义信息的融合,减少空间信息的丢失。经过模型概要可知,本文模型的具体流程如下,如表 2-1 所示。
(1)input:输入图像大小为416×416×3。
(2)下采样阶段:
- 1)block 1:输入图像大小为416×416×3,使用3×3的64通道卷积核进行2次卷积,再进行减半池化;
- 2)block 2:输入图像大小为208×208×64,使用3×3的128通道卷积核进行2次卷积,再进行减半池化;
- 3)block 3:输入图像大小为104×104×128,使用3×3的256通道卷积核进行3次卷积,再进行减半池化;
- 4)block 4:输入图像大小为52×52×64,使用3×3的512通道卷积核进行3次卷积。
(3)上采样阶段:
- 1)block 1:输入图像大小为26×26×512,采用2倍反卷积+拼接,然后使用大小为3×3的512通道卷积核进行2次卷积;
- 2)block 2:输入图像大小为52×52×256,采用2倍反卷积+拼接,然后使用大小为3×3的256通道卷积核进行2次卷积;
- 3)block 3:输入图像大小为104×104×128,采用2倍反卷积+拼接,然后使用大小为3×3的128通道卷积核进行2次卷积;
- 4)block 4:输入图像大小为208×208×64,采用2倍反卷积+拼接,然后使用大小为3×3的64通道卷积核进行2次卷积;
(4)output:输入图像大小为208×208×64,使用大小为1×1的3通道卷积核进行1次卷积,得到输出图像大小为208×208×3。
表 2-1 VGG16-UNet 模型概要
| Layer (type) | Output Shape | Param # |
| input_4 (InputLayer) | [(None, 416, 416, 3)] | 0 |
| block1_conv1 (Conv2D) | (None, 416, 416, 64) | 1792 |
| block1_conv2 (Conv2D) | (None, 416, 416, 64) | 36928 |
| block1_pool (MaxPooling2D) | (None, 208, 208, 64) | 0 |
| block2_conv1 (Conv2D) | (None, 208, 208, 128) | 73856 |
| block2_conv2 (Conv2D) | (None, 208, 208, 128) | 147584 |
| block2_pool (MaxPooling2D) | (None, 104, 104, 128) | 0 |
| block3_conv1 (Conv2D) | (None, 104, 104, 256) | 295168 |
| block3_conv2 (Conv2D) | (None, 104, 104, 256) | 590080 |
| block3_conv3 (Conv2D) | (None, 104, 104, 256) | 590080 |
| block3_pool (MaxPooling2D) | (None, 52, 52, 256) | 0 |
| block4_conv1 (Conv2D) | (None, 52, 52, 512) | 1180160 |
| block4_conv2 (Conv2D) | (None, 52, 52, 512) | 2359808 |
| block4_conv3 (Conv2D) | (None, 52, 52, 512) | 2359808 |
| block4_pool (MaxPooling2D) | (None, 26, 26, 512) | 0 |
| zero_padding2d_12 (ZeroPadding2D) | (None, 28, 28, 512) | 0 |
| conv2d_15 (Conv2D) | (None, 26, 26, 512) | 2359808 |
| batch_normalization_12 (BatchNormalization) | (None, 26, 26, 512) | 2048 |
| up_sampling2d_9 (UpSampling2D) | (None, 52, 52, 512) | 0 |
| zero_padding2d_13 (ZeroPadding2D) | (None, 54, 54, 512) | 0 |
| conv2d_16 (Conv2D) | (None, 52, 52, 256) | 1179904 |
| batch_normalization_13 (BatchNormalization) | (None, 52, 52, 256) | 1024 |
| up_sampling2d_10 (UpSampling | (None, 104, 104, 256) | 0 |
| zero_padding2d_14 (ZeroPadding2D) | (None, 106, 106, 256) | 0 |
| conv2d_17 (Conv2D) | (None, 104, 104, 128) | 295040 |
| batch_normalization_14 (BatchNormalization) | (None, 104, 104, 128) | 512 |
| up_sampling2d_11 (UpSampling2D) | (None, 208, 208, 128) | 0 |
| zero_padding2d_15 (ZeroPadding2D) | (None, 210, 210, 128) | 0 |
| conv2d_18 (Conv2D) | (None, 208, 208, 64) | 73792 |
| batch_normalization_15 (BatchNormalization) | (None, 208, 208, 64) | 256 |
| conv2d_19 (Conv2D) | (None, 208, 208, 3) | 1731 |
| reshape_3 (Reshape) | (None, 43264, 3) | 0 |
| softmax_3 (Softmax) | (None, 43264, 3) | 0 |
Total params: 11,549,379 Trainable params: 11,547,459 Non-trainable params: 1,920 | ||
三、环境配置与性能衡量
3.1 环境配置
由于深度学习对 GPU 要求较高,本文采用高配置的“AutoDL算力云”云服务器,使用 TensorFlow-GPU 2.5.0 作为深度学习框架进行猫狗图像分割模型的训练。在训练的过程中,使用交叉熵损失函数作为模型的目标函数,应用 Adam 优化器对参数进行了优化。初始学习率设置为 1e-3 即 0.001。随着训练的进行,根据训练轮数的增加,学习率会自动进行调整。训练 batch size 设置为 4,轮数为 50 轮,实验所用硬件配置如表 3-1 所示。
表 3-1 实验环境配置
| 项目 | 参数 |
| GPU | L20(48GB) * 1 |
| CPU | 20 vCPU Intel(R) Xeon(R) Platinum 8457C |
| 显存 | 100GB |
| 硬盘 | 系统盘:30 GB;数据盘:50GB(免费) |
| 操作系统 | Ubuntu 18.04 |
| 开发语言 | Python 3.8 |
| 深度学习框架 | TensorFlow 2.5.0 |
| CUDA | 11.2 |
3.2 损失函数
损失函数用于描述预测值与真实值之间的差值,通过不断优化模型,使模型收敛,从而最小化模型损失,进而得到理想的模型预测结果。对于猫狗图像语义分割模型而言,猫和狗的类别存在明显不同,因此本文采用交叉熵损失函数(categorical_crossentropy)和 Adam 优化器进行模型训练。为最小化损失函数,设置学习率(learning_rate)调节模型的参数,从而有效衡量模型预测与真实标签的差异,有助于学习和区分猫狗的特征。损失函数以 L 表示,即

式中,N 是类别数量,y 是真实标签的独热编码(one-hot encoding),p 是模型预测的概率分布,i 是类别的索引。
3.3 评价指标
在训练过程中,除了计算模型损失外,还需选取合适的参数评价模型的性能。以标签作为评价标准,除了深度神经网络常用的精确率、召回率及调和均值 F1-Score 指标外,图像语义分割还采用平均交并比(Mean IoU)来完成模型分割性能的评价,以M表示,即

式中,k+1 表示需要预测的类别数量(含图片背景); 表示类别 i 的像素被预测为类别j的数量,故
为正样本,
为假负样本,
为假正样本。
当 F1-Score 的值接近于 1 且 Mean IoU 大于 0.5 时,即认为分割模型具有较好的识别能力。在猫狗图像的分割中,猫狗仅占整个图像的一部分,因此,认为 Mean IoU 大于 0.5 时即可满足实际分割需要。
四、模型训练与预测
4.1 模型训练
4.1.1 模型训练过程
本文采用UNet模型进行猫狗图像分割,模型共进行了50个世代的训练。在训练过程中,首先冻结了前10层(总共33层)以进行冻结训练。为了加快模型的收敛速度和提高猫狗特征的学习效果,利用了在ImageNet大型数据集上预训练的VGG16模型的权重进行迁移学习。通过这种迁移学习方法,不仅可以加速模型的收敛,还使得模型更好地适应新的数据集,提高了猫狗图像分割任务的性能和效果[5]。
在冻结训练中,需要冻结相应模型编码结构的卷积层,这些层在训练过程中保持不变,直接使用预训练权重。训练过程中的具体模型参数详见表5-1。这种策略有助于快速收敛并提高模型性能,通过利用预训练的权重进行迁移学习,模型可以更好地学习猫狗特征并适应新数据集的特点。
表 4-1 分割模型训练参数
| 模型 | 主干提取网络 | 训练阶段 | 学习率 | 批训练规模 | 优化器 | 训练世代 |
| VGG16-UNet | VGG16 | 冻结训练 | 10-4 | 4 | Adam | 50 |
模型训练中的4个参数指标:精确率、召回率、F1-Score 以及平均交并比 Mean IoU 均随着训练世代的变化而变化,具体变化情况如下图所示。
4.1.2 猫狗图像分割训练结果
1. 训练集的准确率和损失率
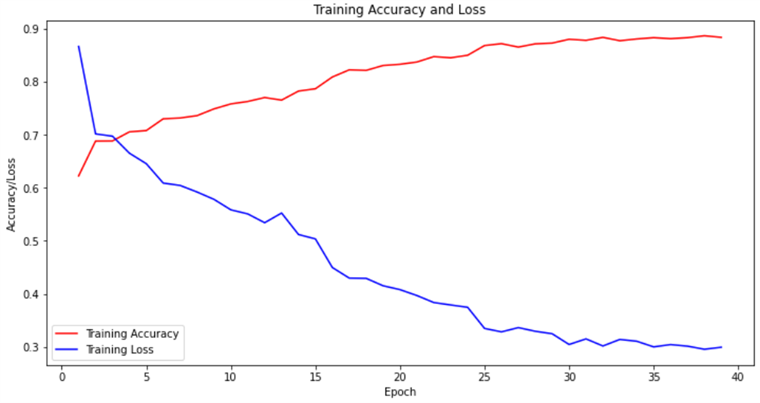
图 4-1 训练集结果
2. 训练集的准确率和损失率
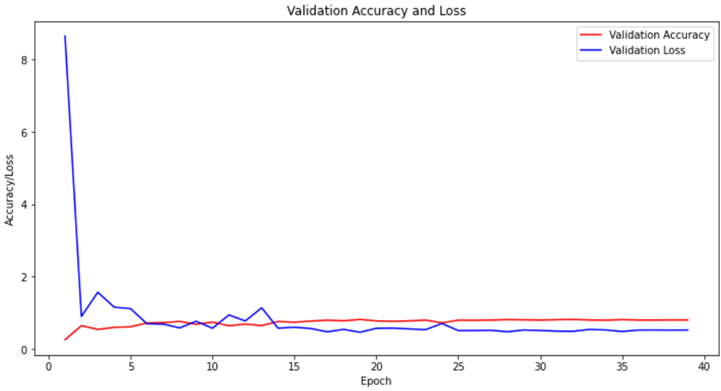
图 4-2 验证集结果
根据图 4-1 和 4-2 的结果显示,经过 50 轮的训练,该语义分割网络模型展现出了令人满意的性能。训练集准确率高达 92.19%,证明了模型在已知数据上的强大学习能力。同时,验证集准确率也达到了 82.29%,显示了模型在未见数据上的泛化能力。训练集损失率最低至 21.38%,而验证集损失率最低为 49.02%,均处于可接受的范围内,进一步证实了该模型在语义分割任务上具有相当的稳定性和有效性。
3. 召回率 Recall 结果
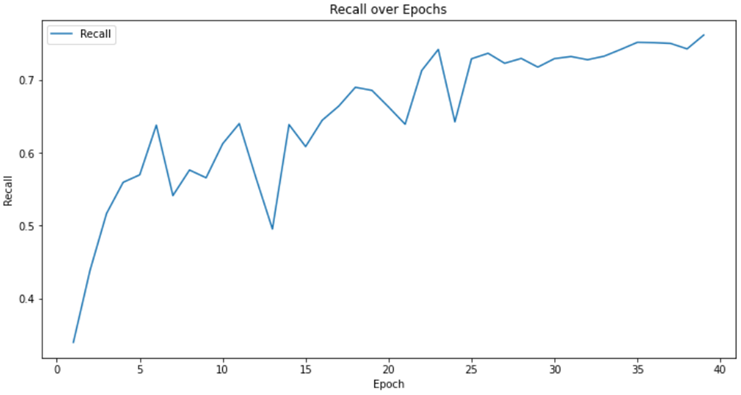
图 4-3 召回率 Recall 结果
4. 调和均值 F1-Score 结果
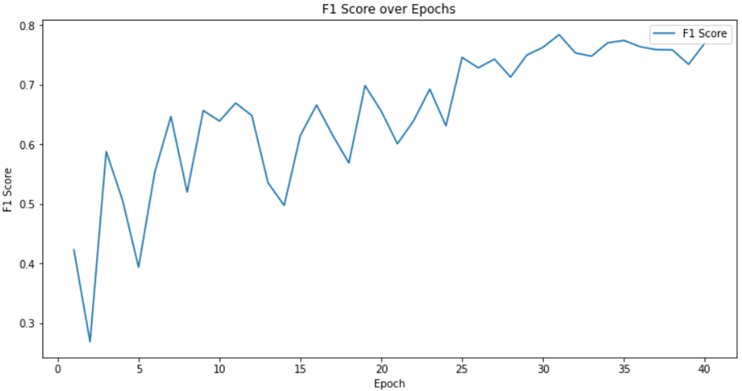
图 4-4 调和均值 F1-Score 结果
5. 平均交并比 Mean IoU 结果
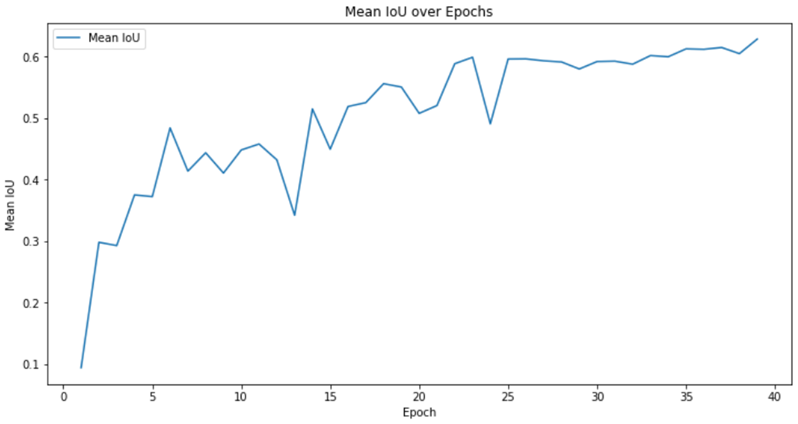
图 4-5 平均交并比 Mean IoU 结果
根据图表展示的召回率(Recall)和调和均值(F1-Score)和平均交并比(Mean IoU)的可视化结果,可以清晰看到模型在训练过程中性能稳步提升。特别是在第 27 轮之后,召回率和 F1-Score 均稳定保持在高于 0.73 的出色水平,,这意味着模型能够准确识别出目标区域。同时,Mean IoU 持续保持在 0.6 以上,也持续保持在 0.6 以上,充分展现了模型在语义分割任务中的精确度和有效性。这些卓越的性能指标进一步验证了该模型在语义分割领域的强大实力。
如表 4-2 所示,模型在各项评估指标上均取得了最佳结果,进一步证明了 VGG16-UNet 语义分割模型在识别能力上的优越性。
表 4-2 模型评估指标最佳结果
| 评估指标 | 值 |
| 训练集准确率 | 92.19% |
| 验证集准确率 | 82.29% |
| 训练集损失率 | 21.38% |
| 验证集损失率 | 49.02% |
| 召回率(Recall) | 0.7779 |
| 调和均值(F1-Score) | 0.7750 |
| 平均交并比(Mean IoU) | 0.6460 |
4.2 模型预测
4.2.1 待预测猫狗图像的模型分割过程
在上述训练中,定义三个类别分别为 background、cat、dog,在接下来检测过程当中,将分别将待检测图片转化为上述构建模型所需形式,带入已经训练好的模型进行像素值类别判断,并且赋予其类别颜色,这里背景颜色为黑色,猫的颜色为红色,狗的颜色为绿色。
在模型预测中,UNet 模型经初始化后,加载预训练权重 h5 文件,提取验证集损失率相对较低的 h5 文件,以确保模型具备最佳预测性能。遍历测试集文件夹中的所有图像时,每张图像首先使用 PIL 库读取并保存其原始尺寸。将图像调整为模型输入所需的固定尺寸,并归一化图像像素值至 0-1 之间。处理后的图像被输入到模型中,进而模型输出每个像素的类别预测结果。
基于模型输出的类别预测结果,生成彩色的分割图像。为了保持图像的视觉一致性,分割图像调整回原始大小并保存到指定目录中。为了便于直观对比,将原始图像和分割图像进行混合,生成混合图像,并保存到另一个目录中。
通过拼接展示将原始图像、分割结果图像及混合图像分别拼接成大图,便于对模型性能进行全面评估。在整个过程中,图像的处理与可视化展示实现了对测试图像的高效处理,为语义分割任务提供了完整的解决方案。
预测结果的可视化效果如图 4-6 至 4-8 所示。
4.2.2 预测结果可视化
1. 原始图像

图 4-6 原始图像
2. 分割结果图像

注:黑色代表 background(背景),绿色代表 cat(猫),红色代表 dog(狗)。
图 4-7 分割结果图像
由上述分割结果图像可以清晰看出,图像中包含黑色、绿色、红色三种类别颜色,分别代表背景、猫、狗。从轮廓看,猫狗的提取效果较好,但从颜色来看,部分猫狗的类别提取存在些许偏差,但基本可以分割出猫和狗的图像。从总体上来看,该 VGG16-UNet 语义分割模型的预测效果较好,基本可以适用于二分类或者更多类别的语义分割场景中,具有一定的普适性。
3. 混合图像
为了便于直观对比,将原始图像和分割图像进行混合,生成混合图像,并保存到另一个目录中。这种混合图像通过将分割结果叠加在原始图像上,使得分割区域与原始图像的细节清晰可见,进而更加直观地观察模型的分割效果,评估模型在实际场景中的表现。这些混合图像在视觉上提供了清晰的参考,有助于进一步优化和调整模型。混合图像的可视化结果如下图所示。

注:黑色代表 background(背景),绿色代表 cat(猫),红色代表 dog(狗)。
图 4-8 混合图像
五、总结与展望
5.1 总结
本实验探讨了基于 VGG16 和 UNet 架构的语义分割模型在猫狗图像提取中的应用。通过使用 VGG16 作为编码器捕获图像的低层次特征,并结合 UNet 解码器实现逐步上采样,还原图像的空间分辨率,取得了较为理想的分割效果。
在数据预处理方面,对图像和标签进行了归一化处理,并通过生成器按批次提供数据,保证了模型的稳定训练。使用预训练的模型权重进行初始化,进一步提升了模型的收敛速度和性能。通过设定 EarlyStopping 和 ReduceLROnPlateau 等回调函数,有效防止了过拟合现象的发生,同时调整了学习率,确保模型在不同训练阶段的稳定性。
模型训练过程中,自定义的 MetricsCallback 记录了每个 epoch 的召回率、F1 分数和 mIoU,提供了全面的评估指标。训练结果显示,模型在训练和验证集上的准确率和损失率均有显著改善,且自定义指标的变化趋势也表明模型性能逐步提升。冻结前 10 层进行训练的策略有效利用了预训练权重的特征提取能力,增强了模型的泛化性能。
在测试阶段,通过对测试集图像进行预测,生成了分割图像并与原图进行混合,得到清晰的分割结果。实验结果表明,基于 VGG16-UNet 的语义分割模型在猫狗图像提取任务中表现出色,能够较为准确地分割出目标区域,且分割结果与原图基本一致。
5.2 展望
未来可以通过多种方式进一步提高 VGG16-UNet 模型在语义分割任务中的性能。首先,可以尝试更复杂的编码器架构,如 ResNet 或 DenseNet,以提高模型的分割精度。增加模型的宽度和深度,并探索多尺度特征融合的方法也是关键,以便更好地捕捉图像中的细节信息。
在数据预处理方面,使用更多的数据增强技术,如随机裁剪、旋转、颜色抖动等,能够扩充训练数据的多样性,提高模型的鲁棒性。这些技术使模型能够更好地适应不同的图像场景,从而在实际应用中表现更加稳定。对标签数据进行更精细的处理,避免噪声和误标,提高标签数据的质量,也有助于提升模型性能。此外,引入半监督学习或主动学习方法,利用大量未标注数据,可以进一步提高模型的泛化能力。
优化训练策略也至关重要。采用先进的优化算法和策略,如 AdamW 优化器和学习率循环调整,可提升模型的训练效率和收敛速度。引入正则化技术如 DropBlock 和 Cutout 有助于防止过拟合,提高泛化能力。
改进评估指标,尝试多元化的评估方法和指标,如 Dice 系数、Hausdorff 距离等,可以提供更全面的模型性能评估。根据实际应用需求,优化模型结构和训练策略,满足实际场景需求。比如在医疗图像分割中,精确的边界检测和细节分割尤为重要,可以采用专门的边界增强技术。
最后,考虑移动端或嵌入式设备部署,通过模型压缩和加速技术实现高效实时图像分割。持续优化和创新,将为各类图像分割任务提供更广泛的应用前景,推动医疗图像分析、自动驾驶和遥感图像处理等领域的发展。努力探索新技术和方法,提供更精准高效的图像分割解决方案,不断推动各行业发展。
通过持续的优化和创新,基于 VGG16-UNet 的语义分割模型在各类图像分割任务中的应用前景将更加广阔。在医疗图像分析、自动驾驶和遥感图像处理等领域,通过改进可以提升模型的应用效果,推动相关领域的发展和进步。新技术和方法的引入将提高模型性能,为各行业提供更精准、高效的图像分割方案。
参考文献
[1] 赵兴旺,吴治国,刘超,等.基于CBAM VGG16-UNet语义分割模型的建筑物提取研究[J/OL].齐齐哈尔大学学报(自然科学版),2024,(03):1-7.
[2] 张伟光,钟靖涛,呼延菊,等.基于VGG16-UNet语义分割模型的路面龟裂形态提取与量化[J].交通运输工程学报,2023,23(02):166-182.
[3] 谢跃辉,李百寿,高豫川.基于LBP纹理与SegNet网络的灾损建筑物提取[J]北京测绘2023,37(03):397-401.
[4] 孙凌辉,赵丽科,李琛,等.融入CBAM的Res-UNet高分辨率遥感影像语义分割模型[J].地理空间信息,2024,22(02):68-70.
[5] 陈卫国,莫胜撼.基于迁移学习和逻辑回归模型的花卉分类研究[J].南方农机, 2024,55(01):139-143+151.
![Spring学习03-[Spring容器核心技术IOC学习进阶]](https://i-blog.csdnimg.cn/direct/10957890f11d4a2bbfd5161063c717e2.png)


![【BUUCTF-PWN】7-[第五空间2019 决赛]PWN5](https://i-blog.csdnimg.cn/direct/fae5708be3dc49ff9957efef258c59c2.png)



![[C++][CMake][CMake基础]详细讲解](https://img-blog.csdnimg.cn/direct/8beb5fc35be346f5ae7b25a4c4eb4165.png)